Proyecto de Web Scraping
Automatización de recolección de datos con Selenium y Requests
Este proyecto integra diferentes aproximaciones de Web Scraping utilizando librerías como
Selenium y BeautifulSoup, así como herramientas auxiliares como
webdriver_manager. Con ello se busca extraer datos de diversas páginas web
de manera automática y programática.
A continuación, se muestran algunos fragmentos de código donde se aplican buenas prácticas, como limpieza de texto, manejo de precios y scroll dinámico en sitios con contenido que se carga de forma parcial.
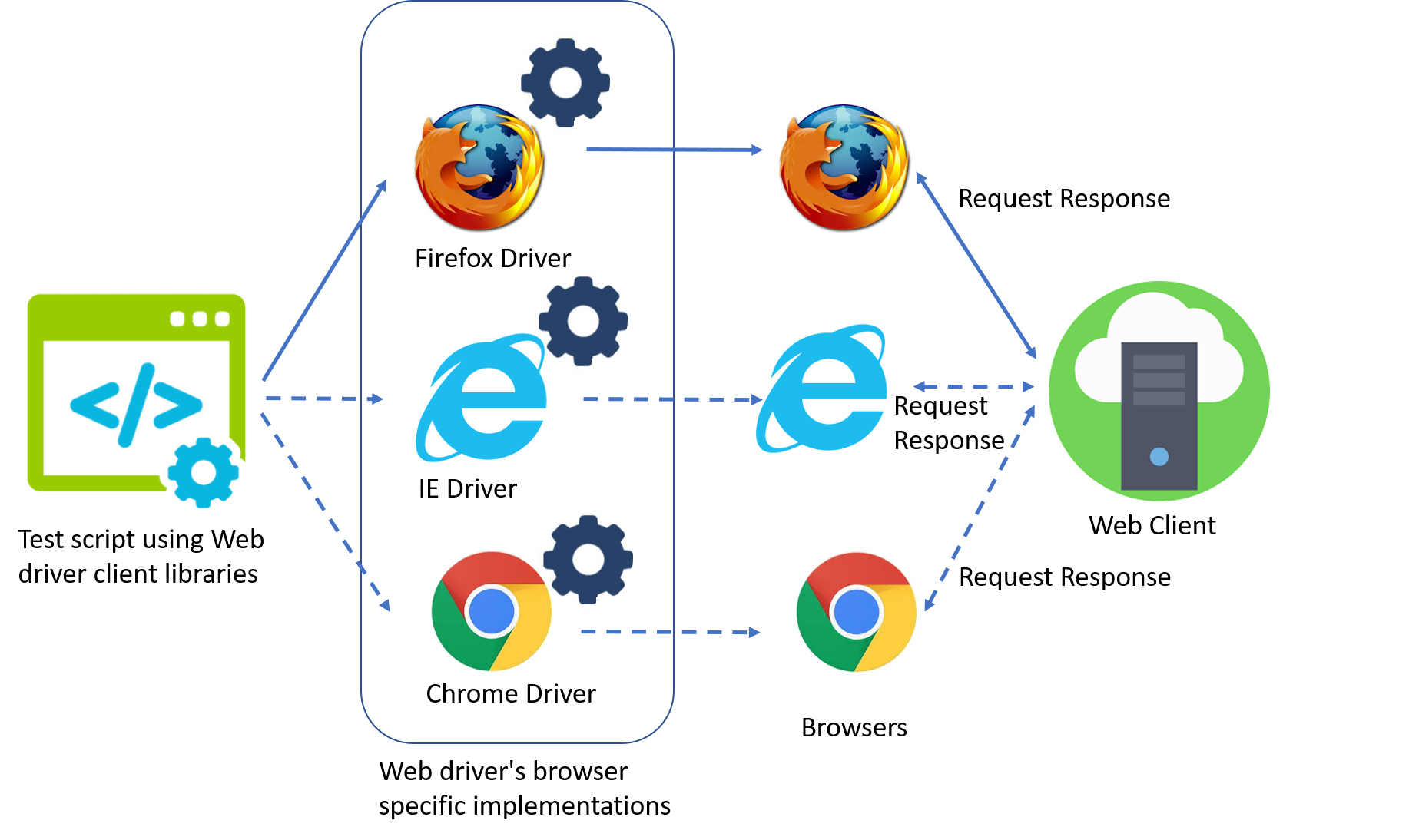
Usar Selenium permite automatizar un navegador real para hacer login, resolver pantallas intermedias y realizar clics. De esta manera se pueden extraer datos de páginas que renderizan elementos de forma asíncrona y no se limitan únicamente a HTML estático.
1. Clase Web_driver() y funciones auxiliares
Este fragmento de código inicializa un navegador Chrome, define la función
get_gender() para determinar el género del producto a partir de la URL,
así como métodos de limpieza de textos y precios:
class Web_driver():
def __init__(self):
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
self.driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
def get_gender(self, pag):
# ... definición de lógica para 'hombre' | 'mujer' ...
def arreglar_texto(self, texto_in):
# ... elimina espacios y caracteres especiales ...
def arreglar_moneda(self, valor_in):
# ... limpieza de valores monetarios ...
def actualizar_altura(self, x_path):
# ... desplaza el scroll hasta la altura de un elemento ...
2. Scraping completo de productos
En la función true() se define el proceso de scrolling, recolección de
URLs, productos (nombre, precio, imagen) y finalmente la creación de un
DataFrame para almacenar los resultados:
def true(self):
print('=============True Scraping==============')
# Definición de las páginas a usar
url = ['https://trueshop.co/pages/hombre','https://trueshop.co/pages/mujer']
# ...
lista_diccionarios = []
for pagina in paginas_completo:
self.driver.get(pagina)
# ...
while True:
# scroll + extracción de items
# ...
lista_diccionarios.append({
'fecha': date.today(),
'foto': foto,
'item': foto,
'posición': posicion,
'marca': "True",
'pag': pagina,
'nombre': nombre,
'precio': precio_visible,
'precio descuento': precio_antiguo,
'categoria': categoria,
'genero': genero_item,
'link': link
})
# ...
return pd.DataFrame(lista_diccionarios)
De este modo se construye un dataframe que posteriormente puede ser exportado a formatos como CSV o Excel, facilitando el análisis posterior.
También se incluyen ejemplos de automatización de login en servicios de streaming:
Prime Video y Star+, para simular usuario, contraseña,
y extraer información de series, episodios y enlaces directos.
3. Automatización de login (Prime Video)
El siguiente ejemplo utiliza Selenium para:
- Navegar a la página de
primevideo.com. - Rellenar credenciales.
- Ingresar el término de búsqueda.
- Almacenar enlaces de cada episodio.
driver = webdriver.Chrome()
driver.get("https://www.primevideo.com/")
# Hacer clic en el botón "login"
login_button = driver.find_element(By.XPATH, './/a[@class="dv-copy-button"]')
login_button.click()
# Ingresar email
email_field = driver.find_element(By.XPATH, './/input[@type="email"]')
email_field.send_keys(user_name)
# ...
4. Automatización de login (Star+)
Similarmente, para Star+ se requiere manejar pantallas intermedias (botones de "Continuar", elección de perfil, etc.). Aquí se ilustra la secuencia de pasos:
driver = webdriver.Chrome()
driver.get("https://www.starplus.com")
# ...
path = './/a[@href="/login"]'
login_button = driver.find_element(By.XPATH, path)
login_button.click()
# Continuar y aceptar
path = './/button[@aria-label="Aceptar y continuar"]'
continue_button = driver.find_element(By.XPATH, path)
continue_button.click()
# ...
Con esta aproximación, hemos automatizado la extracción de información en varios contextos: tiendas
en línea y servicios de streaming. El uso de Selenium y BeautifulSoup
permite adaptar el scraping a distintos escenarios, manejando logins, scroll infinito y parsing
de HTML. De esta forma, se pueden generar datasets para posteriores análisis de negocio
o simplemente para centralizar y administrar el contenido que más nos interesa.